
Will Google’s Instant Answers Threaten, Even Destroy, Search Giant’s Future
LONG ISLAND, NY – This is a theoretical opinion and is far from fact, but I thought about it today and I’m going to share it with my readers, as I ordinarily do here on this site, a place where my thoughts about the Internet, meet the Internet itself – and my ramblings are meant, not just to entertain, or act as some therapeutic outlet, but to help form options, influence discussion, create dialog and educate.
Today, we will touch on something that is a growing problem for web publishers of all sizes and continues to threaten web businesses as many site owners all too well know. You see, the writing is on the wall for Google, the massive search engine company everyone now realistically knows and accepts as the single best search engine in the world – to at some point, fall victim to a massive copyright infringement antitrust action, despite the over 400 lawyers which make up its legal team.
How this hasn’t happened yet is quite bizarre in my option.
For instance, when Google started out roughly twenty one years ago, it was a great tool for “finding” the best information, in the shortest amount of time known to man, which is why it grew so popular even creating its own word in the dictionary; “Goo-gle” verb: to search for information about (someone or something) on the Internet using the search engine Google.
However, over the years, Google has fundamentally changed its processes, purpose and mission; it has metamorphosed from a single tool for “finding” information, and transformed into a “provider” of information. The only problem is the information being provided, in most cases, isn’t theirs.
In current times, Google prefers not to help you “find” anything at all; it wants to “deliver” the information you seek, based on content it ‘collects’ and stores from third party sources. Basically, what Google does, and so effectively I might add, is crawls and scans the entire Internet gathering up all Internet content, inserting it into a giant database, and then serving the content, to users when it deems appropriate.
Featured Snippet Example: https://support.google.com/webmasters/answer/6229325?hl=en
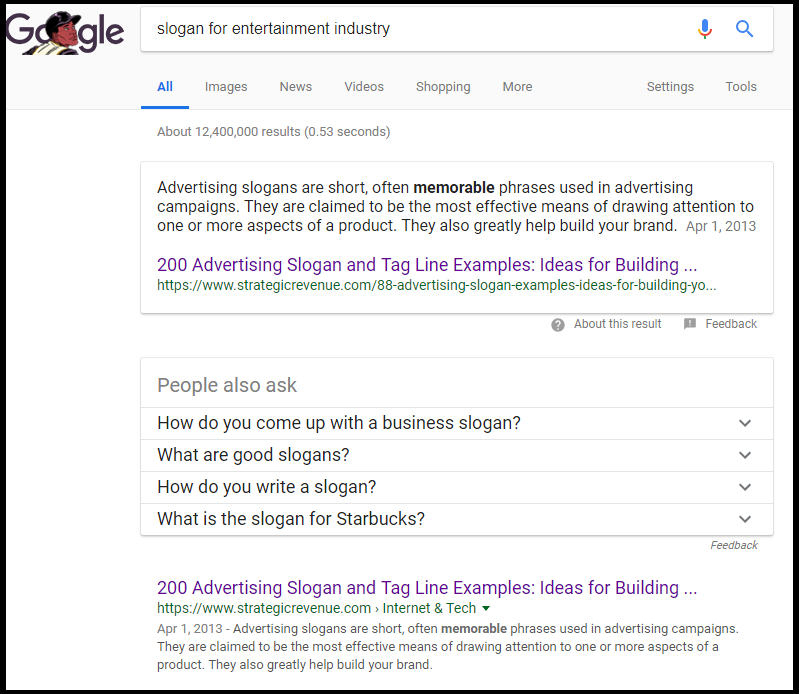 With an example using this site, Google tries its best to define and answer the question, while presenting similar questions, all in an attempt to prevent the click to the site being necessary.
With an example using this site, Google tries its best to define and answer the question, while presenting similar questions, all in an attempt to prevent the click to the site being necessary.
This practice is hurting the original creators and providers of the information by delivering less and less Internet traffic to web sites which prevents web publishers from serving users – ultimately leading to declining ad revenue and market share. Google is able to effectively gobble up or even ‘steal’ the content and Internet traffic preventing visitors from ever having to click on a website at all. Miraculously, much of the web and government regulators are silent [or unsuccessful in preventing] this highly inappropriate practice.
And we are seeing growing trends with this information theft in the form of quickly delivered movie times, event listings, weather, sports scores and all sorts of information which once enabled publishers to be ‘rewarded’ by the Internet traffic they received by Google’s searchers of information. Now instead, Google is the beneficiary, by using the content of others, delivering content not from the publisher whom created it, but from its own database and retrieval process, serving answers based on what it in its sole discretion, has obtained from various third party sources.
I have been watching search engines change and evolve for near twenty years, and Google, for the most part, no longer wants users to leave Google itself for any reason, unless it’s either clicking on an ad, or utilizing one of its many other services such as YouTube, or Google Maps. If Google can provide the information a user is looking for, it’s going to deliver it with little worry or concern about where it may have originated from and what effect this process might have on the source, the actual provider of the information – the content creator.
It’s sort of like pirating content on steroids; like bringing users to third party websites is a worst case scenario to be used only when all other options have been exhausted.
I’m not sure how realistic it is to expect this to continue. I believe it severally bends the envelop between fair use, which is the exception in copyright law that permits limited use of copyrighted material without acquiring permission from the rights holders, because limited information is intended to promote ‘wider distribution’ and use of creative works, but Google eliminates distribution, which causes it, in my opinion, to fail the four-factor test leading to a massive defaulted misuse of copyrights worldwide.
U.S. fair use factors:
- the purpose and character of the use, including whether such use is of a commercial nature or is for nonprofit educational purposes; (COMMERCIAL)
- the nature of the copyrighted work;
- the amount and substantiality of the portion used in relation to the copyrighted work as a whole; and (ELIMINATES NEED FOR WHOLE PORTION)
- the effect of the use upon the potential market for or value of the copyrighted work. (ELIMINATES SOURCE VALUE)
Certainly Google’s has changed its processes, purpose and mission over the years. It’s even developed a surprisingly guilty conscience, moving and deemphasizing its “Don’t be evil” motto once leading it’s corporate code of conduct to now succeeding it as merely a concluding statement.
I believe it would be a wise choice for Google to take a couple of steps backwards when it comes to its featured snippets and knowledge graph technologies before it finds itself a victim of copyright infringement and/or even racketeering through its own peer-to-peer network of computers which facilitate content sharing near similar to cases as old as Metallica v. Napster, Inc.

About The Author: John Colascione is Chief Executive Officer of SEARCHEN NETWORKS®. He specializes in Website Monetization, is a Google AdWords Certified Professional, authored a how-to book called ”Mastering Your Website‘, and is a key player in several online businesses.
Add STRATEGIC REVENUE as a Google Preferred Source to see more of our business, technology, and digital strategy coverage in Google Search.
Add Strategic RevenueYou can now select the categories you're interested in and receive email updates when new articles are published in only those categories.


This is fair use. Google only provides a snippet, you then have to go to the original site for more info. Google is out of control and fined by the EU. However with a multi million dollar lobby team Washington will do little . And I think about this also. That idiot yang should have sold yahoo to bing for a premium and they would have 30+ percent of the search mkt. Yang rejected the offer stock price slumped and verzion bought yahoo. This hurt everybody. Google has no competitor. and evolves unabated adversely effecting everyone.